2025-12-30
Subgraphs Suck: Crypto Data Infra is Changing
It's time to love your data again
In the early days of DeFi somewhere after 2017, Ethereum needed an upgrade to query data. Subgraphs were a breakthrough. Nobody wanted to run their own indexing infra and database just to power their frontends. Subgraphs offered the resolution: define a schema, write mappings, deploy and query through GraphQL. The first wave of DeFi and other dApps used Subgraphs to power their data infra and frontends. Crypto has changed and Subgraphs can’t keep up with the needs of builders. Chains are faster, we have more chains (and will get exponentially more), we have different VMs. How did we get here and how do we move to better data infra for crypto builders and companies?
Note that when I say Subgraphs in this article, most of these problems apply to Substreams too. These are just database syncs from Subgraphs and thus inherit the underlying problems.
Why Subgraphs Made Sense
Ethereum between 2017 and 2020 was smaller, with lower onchain activity, less protocol complexity and real-time analytics were underappreciated. Most applications only needed to have a read-layer to surface contract state. Teams were less bothered with engineering data pipelines, warehousing, streaming, reliability and were mostly on a single chain. Subgraphs made builders avoid data engineering in their own databases and templates were readily available through The Graph. Forking a protocol was very common and thus also the Subgraph was forked to save on developer time. Even if performance from The Graph's Subgraphs was sub-par, other companies (like Goldsky) would take the management out of users hands.
Subgraphs spread widely and became the default for developers. They weren’t adopted because they were the best solution, but they were readily accessible and developers took short cuts in data engineering.
Crypto Evolves, Subgraphs Do Not
Today crypto is fundamentally different. We have an explosion in the number of chains, dAppchains, subnets. We have various alternative VMs like Solana VM or Move VM (with their dialects). The block times of chains are getting way lower and the volume of data goes up. These are all signals the market is maturing, is specializing and is getting adopted.
The needs change from developers since not only contracts need to be read out from the blockchain, but data from wallets, blocks, individual transactions and networks too. Instead of only powering an interface or a simple dashboard, good indexers and pipelines are now essential in on-chain trading, risk-modeling, compliance, fraud detection, user analytics, business intelligence, etc. Indexing infrastructure and tooling needs to support all use cases.
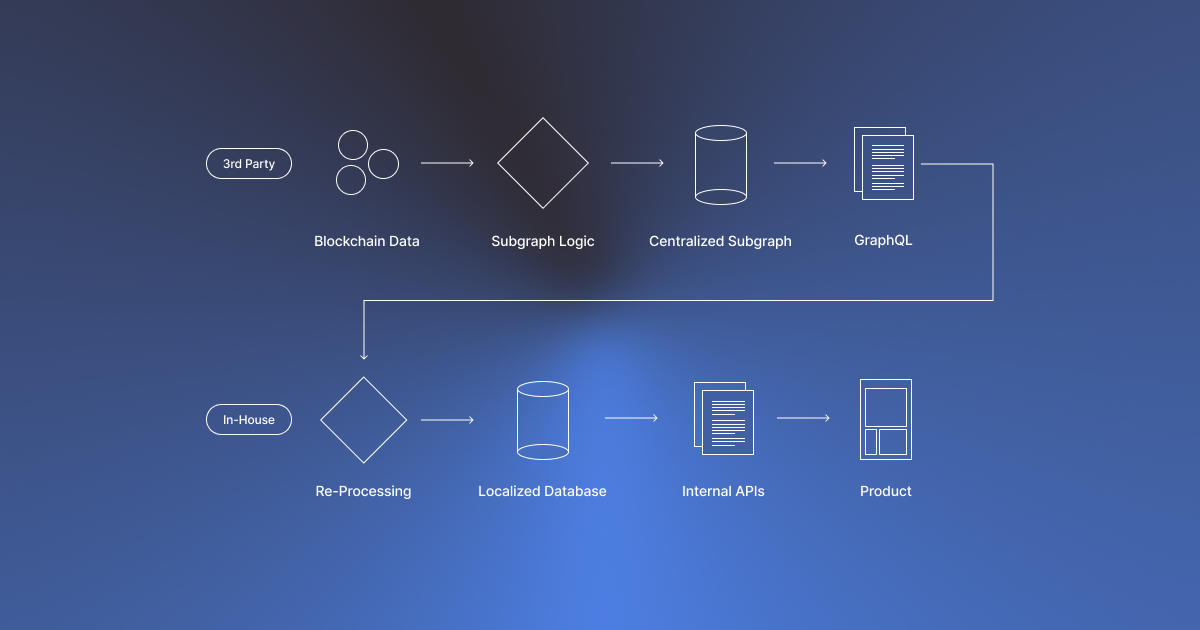
At the core of the problem is Subgraphs design. Subgraphs can’t keep up by being contract-centric, while Subgraphs combine the actual indexing logic, database structure and the storage in one product:
- When data volumes increase, Subgraphs lag behind the chain head and latency increases.
- When mappings or contracts change, developers are forced to re-index. For The Graph this could be painstakingly slow, so various providers would make improvements. A bandaid solution to fix the symptoms, not the underlying problem.
- Subgraphs are single chain and thus developers from multichain projects are forced to maintain multiple databases for similar data.
- Subgraphs are optimized for EVM, leaving other VMs underserved.
- Being a closed off database, only specific data can be collected with limited control over the actual database. If pipelines need to merge in other data (offchain, metadata, user data) first data has to be recollected and re-transformed.
- Lock in with GraphQL. A very specific query language (not at all used for single data sources) is used to query the data. While developers might have a need for other query languages or a query language normal functioning humans like to use like SQL.
I’ll stop there. This list is long enough. Sadly there is more, but I can’t leave you with nightmares. The result is slow dashboards, products stalling, revenue or usage loss and even exploits.
Why TF are Developers Still using Subgraphs?
First of all, familiarity. Developers are used to these Subgraphs in early development, even if it hurts them later. Forks are still frequent in crypto, which leads to building on outdated assumptions. Furthermore, crypto teams might lack expertise in data engineering or lack time to build out better solutions. Even attempts to modernize the model with Substreams fail because they expose the same flaws. Streams do not solve composability, transformations, unification of data and still works contract based.
Various major businesses are built on top of servicing Subgraphs to builders, which creates an illusion crypto data is supposed to be excessed while most of these businesses are mostly painkillers for the pain of handling Subgraphs, not an improvement of the Subgraph infra. Add to this hackathon sponsoring, which then gives early builders a lock in and early education on deprecated solutions.
Luckily most of these businesses and even The Graph itself are sunsetting Subgraphs, researching new solutions, pivoting to other data infra services (even out of indexing) or deploying more modern products. Read through some of the newer product releases (like The Graph Amp) and read between the lines. You’ll find a change in infra and wording. Alchemy for example sunsets the Subgraph business as a whole.
The Next Generation of Crypto Data Infra
The industry has a need for systems that treat blockchains as high-volume, high-throughput and high-resolution. Data streams need tooling that can filter, transform, decode for any business need. Instead of only contract-focussing, the focus has to expand to wallets, transactions, trades, blocks, cross-chain flows, liquidity movements, metadata and network-level statistics.
The feature list for better solutions includes:
- Streaming instead of polling
- Separation of sourcing and computation from storage
- The ability to reprocess and alter pipelines without re-indexing or restarting the infra
- Analytics- and query-ready outputs instead of predefined and raw tables
- Filter, decoding and transformation options to create the desired schemas and unlock unification across chains and even VMs
- Multi-chain pipelines
- Scalability to ensure throughput
- Performance to support real-time use cases
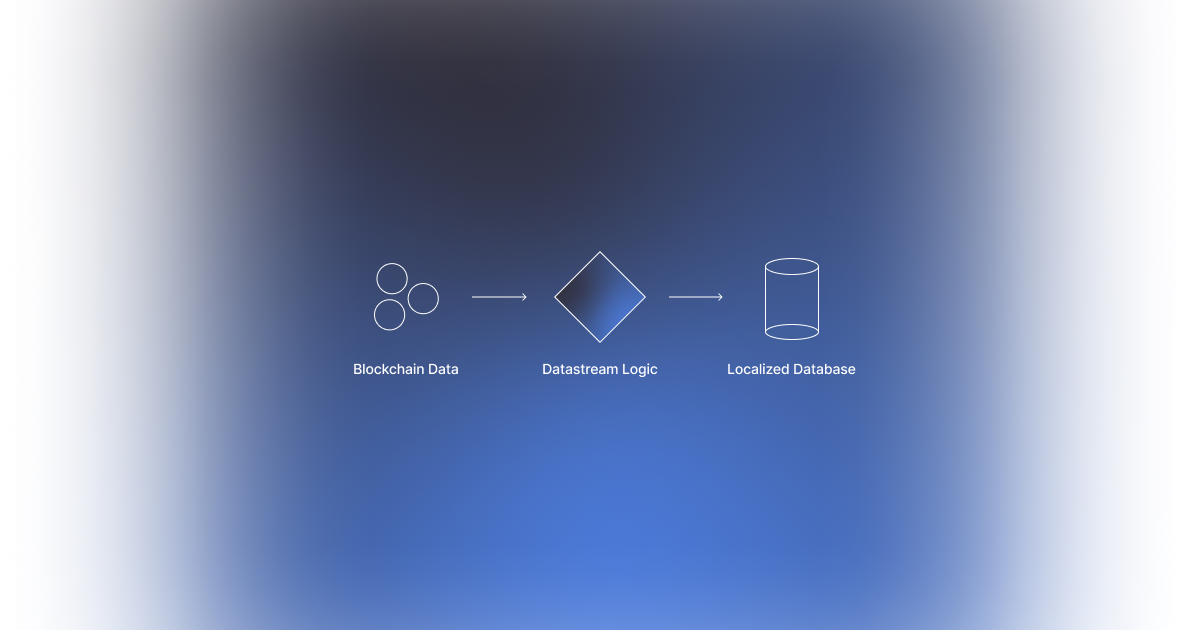
Crypto is scaling, which requires the data infra to scale with it. I’m happy to be building towards better solutions with Indexing Co on both our Pipelines, The Neighborhood and dedicated data infra, while also applauding new developments from parties like The Graph (with Amp) and SQD (with Portal). My goal with this article is not to show the market who has the better solution. The better solution will vary based on the actual product being built and needs from a business. With better and a bigger variety of solutions we can see builders finding the data infra for their product and workflows. The future will hold both more specialized and more generalized solutions that help builders deploy faster, save on development time and increase revenue because of the underlying data infrastructure being more performant.
Subgraphs Suck. It's time to love your data again.